Читайте про инструмент письменного переводчика OmegaT в первой статье. Здесь же будет продвинутая магия: создание своей TMX, редактирование чужой, подключение машинного перевода и продвинутая проверка на ошибки.
- Подключаем машинный перевод
- Проверяем на ошибки
- Открываем и редактируем TMX
- Создаём ТМX
- Считаем объём проекта
- Объединяем и разделяем сегменты
Как добавить машинный перевод
В некоторых ситуациях машинный перевод (такой, как Google Translate) может помочь переводить быстрее. OmegaT можно настроить таким образом, чтобы прямо в её интерфейсе отображался машинный перевод сегмента, который вы можете использовать напрямую или очень быстро редактировать.
В OmegaT можно подключить такие системы, как Google Translate, Microsoft Translator, IBM Watson и Яндекс.Переводчик. Для этого получите API-ключ одного из сервисов, а затем вставьте его в соответствующее поле в OmegaT.
- В OmegaT перейдите в Options -> Preferences -> Machine Translation
- Выберите движок (например Yandex Translate), отметьте его галочкой и нажмите Configure
- Скопируйте API ключ в появившееся поле, нажмите ОК
- В появившемся окне можно задать пароль либо пропустить это действие.
Пароль нужен для того, чтобы защитить ваш API ключ. Актуально для платных переводческих систем.
![]()
Закройте настройки. Теперь в основном окне программы можно нажать на вкладку Machine Translations в нижней части окна. Чтобы окошко с машинным переводом всегда оставалось на виду, нажмите на небольшой значок с двумя окошками.
![]()
Теперь при переходе к новому сегменту программа сделает запрос к движку машинного перевода, получит ответ и покажет его в окне. Горячей клавишей Ctrl+M можно вставить результат в поле перевода.
Как проверить текст на ошибки?
Кроме простой проверки орфографии, которую мы настроили ранее, можно проверить более сложные ошибки, от стилистики до пропущенных тегов. Для этого OmegaT использует открытый инструмент Language Tool. Он поставляется в комплекте с OmegaT, то можно установить отдельно, или подключиться к удалённому серверу.
- Tools -> Check issues (или Ctrl+Shift+V)
- Дважды кликните на ошибке из списка, чтобы перейти к сегменту для редактирования.
По правому клику можно добавить слово в словарь, либо отключить проверку этого типа ошибок.
Слева в окне Check issues можно выбрать фильтр Tags. Он полезен в переводе документов с большим количеством тегов, сохранить которые очень важно — например, при локализации софта.
Совет: Если нужно сохранить теги любой ценой, OmegaT можно запретить создавать финальные документы при наличии ошибок в тегах. Делается это в Tools -> Preferences -> Tag Processing -> Do not allow creating translated documents with tag issues.
Тонкая настройка Language Tool доступна через Tools -> Preferences -> LanguageTool. Здесь можно выбрать, использовать ли встроенный Language Tool, или подключиться к локальному/удалённому серверу. Ниже можно выбрать тип ошибок, на которые программа будет реагировать, например «Пунктуация» -> «Пропущена запятая перед предлогом «И» в сложном предложении«, или «Стиль» -> «Разговорные слова«.
Чем открыть память перевода TMX?
Бывает, что нужно посмотреть, что в файле *.tmx, или даже отредактировать его. Структура у файла довольно простая, и в крайнем случае можно обойтись блокнотом, но это не слишком удобно. OmegaT не может сама открыть TMX для редактирования: память перевода можно только добавить в проект, но не открыть её саму по себе.
Для Windows-пользователей подойдёт бесплатная утилита Olifant из пакета Okapi, скачать можно здесь.
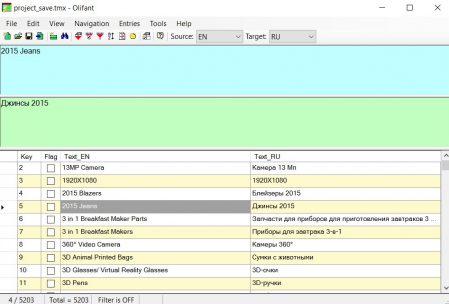
Не вижу смысла писать пошаговую инструкцию к этой программе, всё интуитивно понятно: File -> Open, выбираем память перевода. В верхней части программы оригинал и перевод, в нижней — список всех сегментов.
Через File -> TM Properties можно изменить свойства памяти перевода, такие как языковые пары, кодировку, и прочее.
Как создать свою ТМ?
Допустим, у вас уже есть качественный двуязычный файл, и вы хотите использовать его в проекте как справочный материал. Если файл в формате Excel, где в одном столбце оригинальный текст, а в ячейках напротив — соответствующий перевод, сделать ТМ очень просто.
Существует три способа, которыми я пользуюсь:
- Бесплатная утилита Okapi Olifant
- Встроенный OmegaT Aligner
Онлайн-сервис Translatum.gr(не нужно использовать; создаёт не полностью совместимые ТМ)
Olifant
Программа, о которой мы говорили в предыдущей главе, может не только открывать готовые TMX, но и создавать новые, а так же объединять несколько *.tmx в одну память.
Установите и запустите Olifant, нажмите File -> New и выберите язык исходника и язык перевода. Теперь добавим в новую память двуязычные сегменты: File -> Import. Можно добавить файлы Wordfast, другие *.tmx или Tab-delimited files — другими словами, текстовый файл, где исходный фрагмент и его перевод разделены табуляцией.
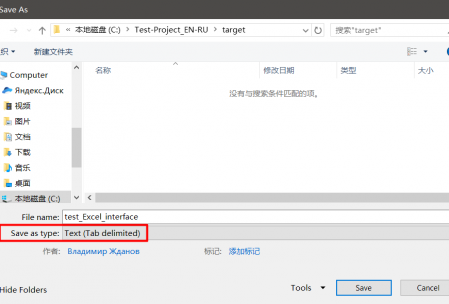
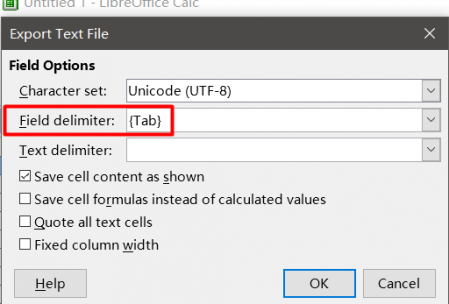
Tab-delimited файл можно создать в MS Excel или Libre Office Calc. Для этого создайте таблицу с двумя столбцами. В первом вставьте исходный текст, в ячейках напротив во втором столбце — перевод.
Сохраните файл в формате Tab-delimited text (в Microsoft Office), либо в Text CSV с параметрами Field delimiter = Tab, Character set = UTF-8 и Text delimiter = *пустой*, если вы используете Libre Office.
Когда импортируете все нужные фрагменты, просто сохраните через File -> Save As в формате TMX.
OmegaT Aligner
В отличие от Olifant, источником служит не таблица с двумя столбцами, а два независимых файла с идентичной структурой, но на разных языках. Чем сложнее форматирование и чем больше отличий, тем хуже будет результат автоматического сопоставления, но его можно подправить вручную внутри Aligner.
Запустите OmegaT, откройте Tools -> Align Files. Укажите языки оригинала и перевода, прикрепите файлы.
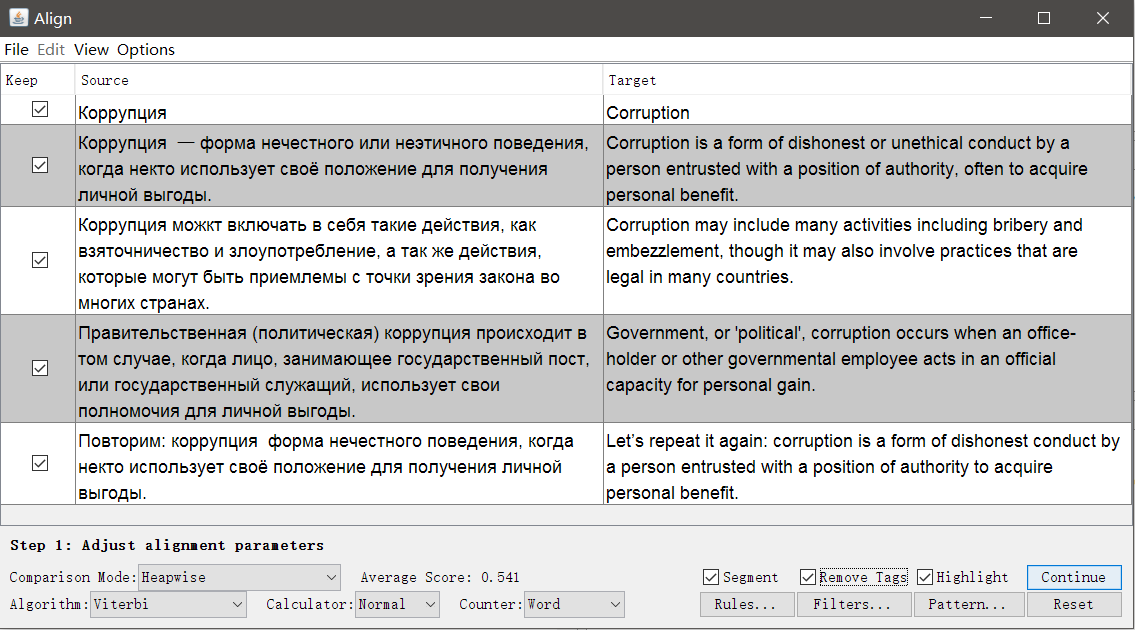
При необходимости можно убрать теги и изменить параметры сегментации. Нажмите Continue, и вы перейдёте к окну с ручной корректировкой сегментов: можно разбить, объединить или переместить сегменты вверх или вниз.
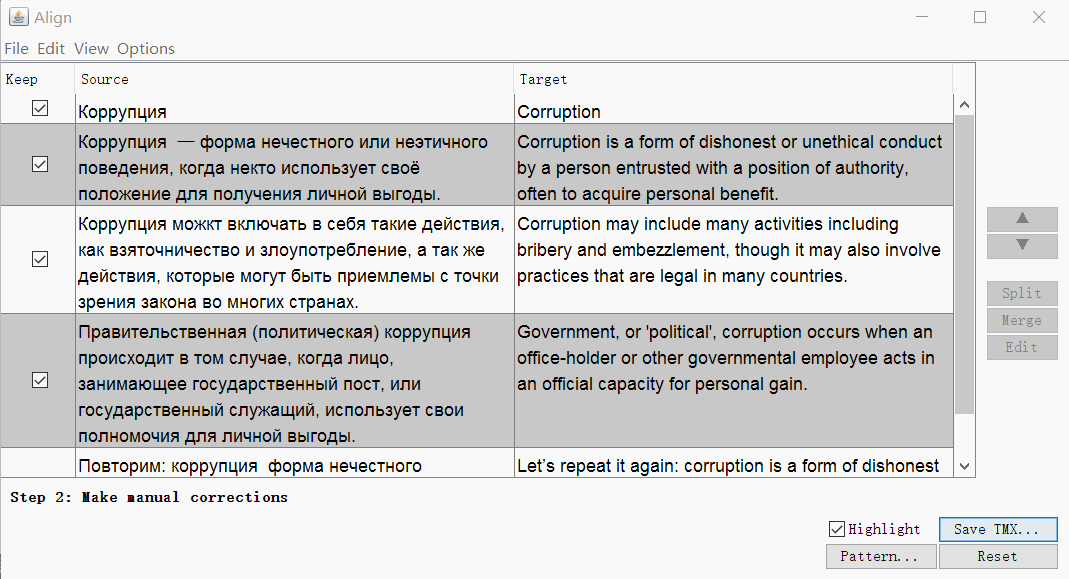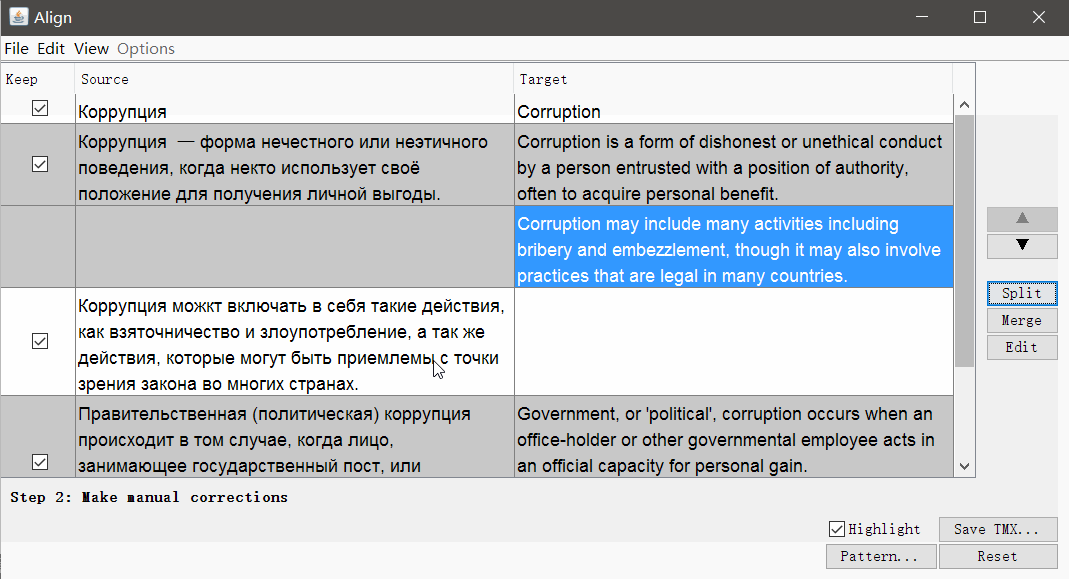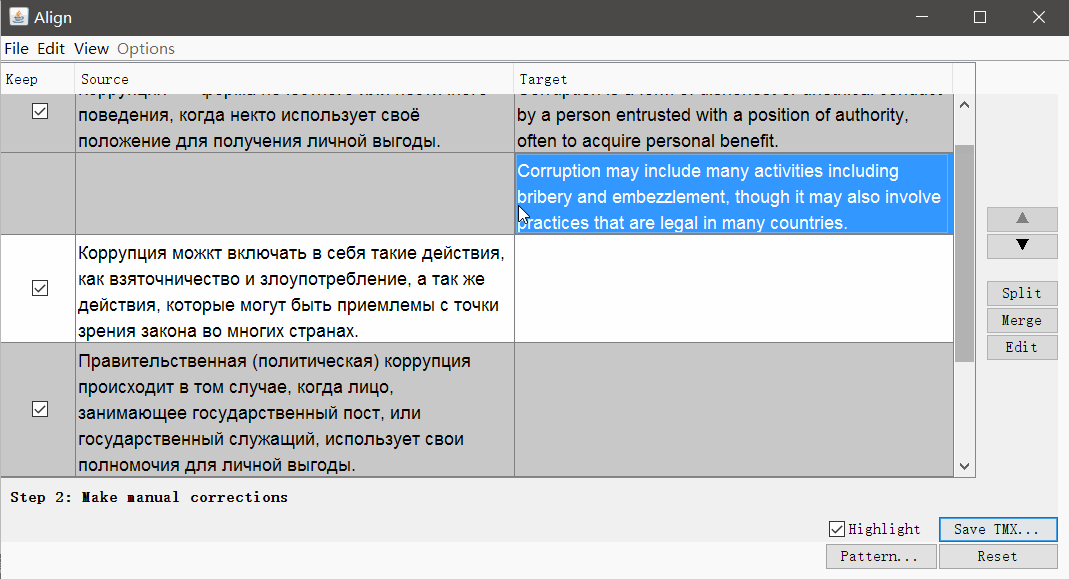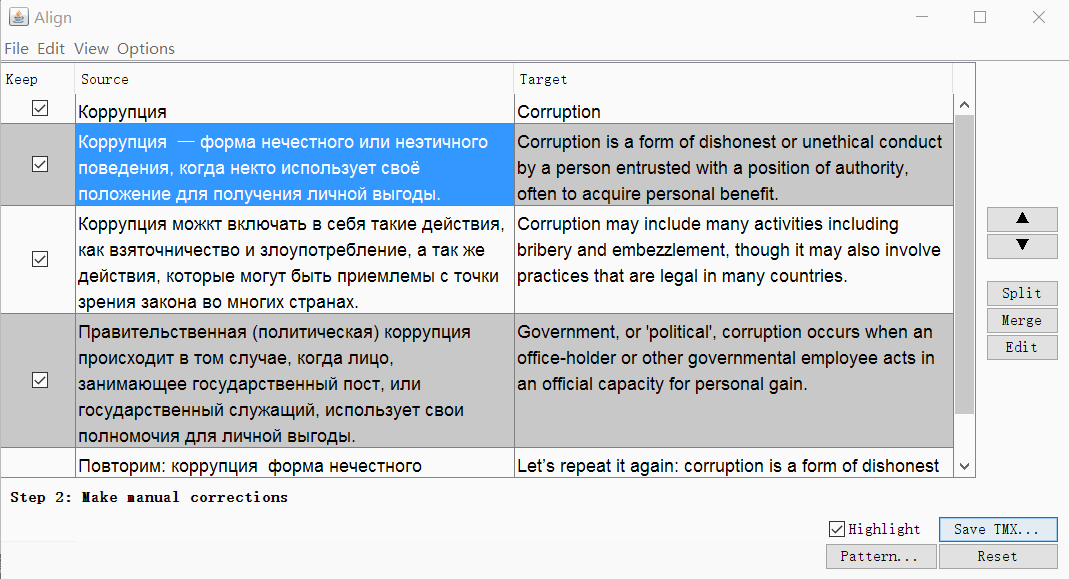
Когда всё выглядит хорошо, сохраните результат кнопкой Save TMX.
Translatum.gr (не используйте с OmegaT)
Работает аналогично Olifant, на входе нужно подать Excel-файл с двумя столбцами текста.
Создайте новый файл Excel (обязательно *.xlsx)В первую колонку вставьте оригинальный текст, во вторую — перевод
Не используйте форматирование, оно не сохранитсяПерейдите по ссылке конвертераВыберите созданный файлУкажите коды исходного и целевого языка
Например, если у вас англо-русский текст, это будет EN-US и RU-RUНажмите кнопку SubmitОткроется страница, с которой вы сможете скачать архив с памятью перевода.
Чтобы использовать память перевода в проекте, распакуйте архив и поместите файл в папку проекта, поддиректория \tm\ (для отображения fuzzy matches) либо \tm\auto\ (для принудительного использования 100% совпадений).
Внимание!
При создании через Translatum есть баг с сегментами, где используются особые символы вроде «>», «<» и даже апострофов. Это создаёт проблемы в Fuzzy Match в OmegaT. Используйте конвертер Olifant, чтобы избежать подобных проблем.
Как посчитать объём проекта
Надо же сказать заказчикам, сколько вы возьмёте за перевод!
На самом деле, нет ничего проще. Откройте проект в OmegaT, перейдите в Tools -> Statistics.
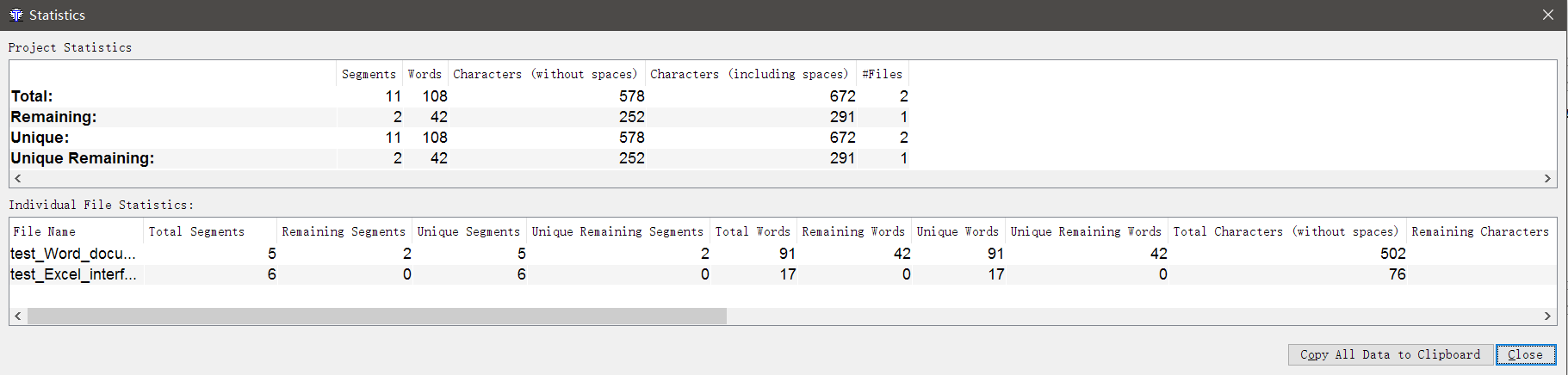
Здесь вы найдёте исчерпывающую информацию о том, сколько слов и символов в файлах, как много здесь повторов, сколько уже переведено и сколько осталось перевести, и так далее.
К сожалению, калькулятора стоимости перевода в OmegaT нет, вам придётся посчитать всё самостоятельно.
Как объединить и разделить сегменты?
Бывает, что вы хотите объединить два сегмента в один, или наоборот, заставить конкретный сегмент разделиться на две части. Если проблема встречается с большим количеством сегментов в проекте, то стоит перенастроить правила сегментации. Если же нужно точечно объединить или разделить сегменты, воспользуйтесь специальным скриптом Merge or split segments:
- Установите скрипт
Скачайте здесь, и распакуйте в папку \scripts (в Windows это может быть С:\Program Files (x86)\OmegaT\scripts\) - Сделайте правила сегментации Project Specific
Project -> Properties -> Segmentation -> отметьте галочку Make the segmentation rules project specific - Задайте скрипту кнопку
Tools -> Scripting, в левой части окна найдите Merge or split segments, выделите его щелчком мыши, а затем нажмите правой кнопкой на одну из цифр в нижней части окна. Например, на единицу. И нажмите Add script.
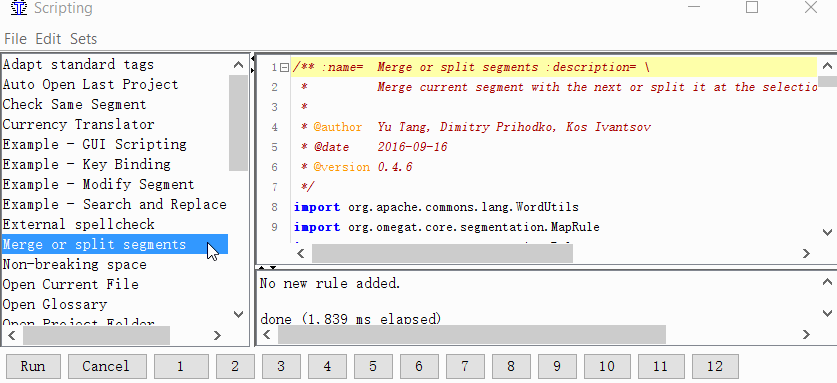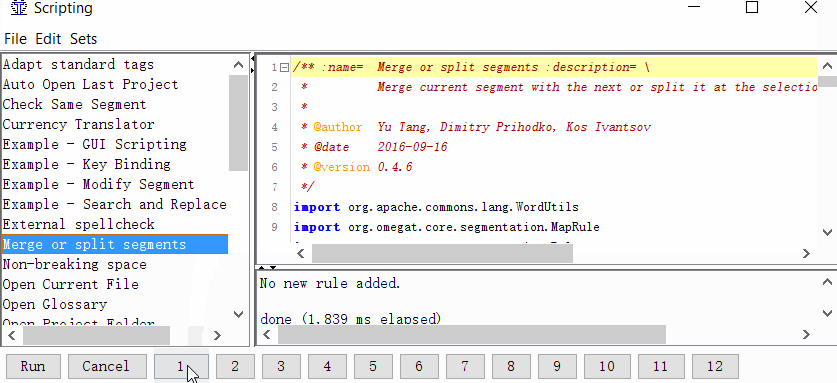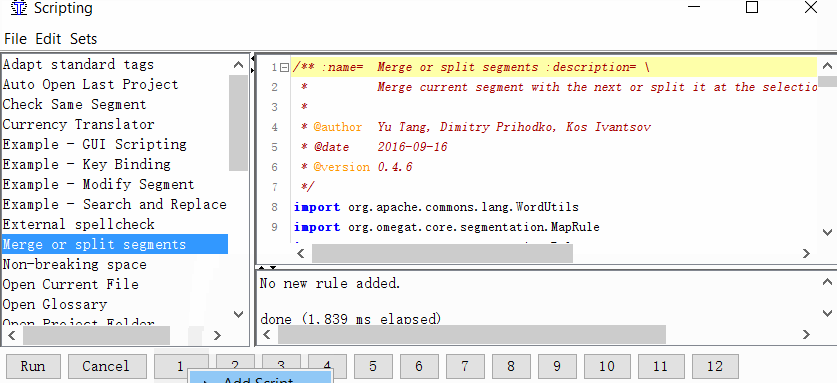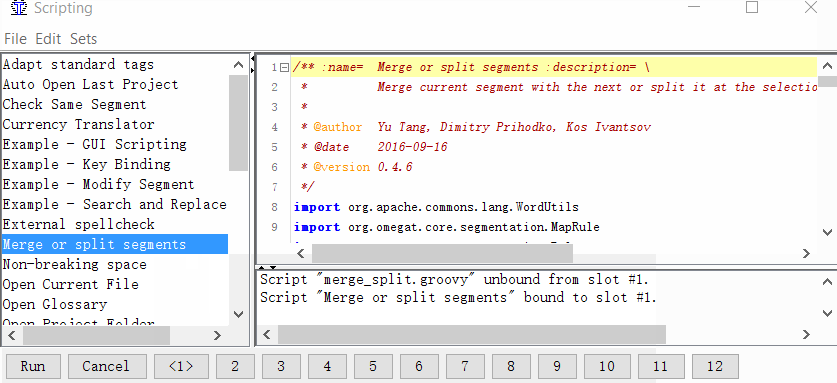
Теперь вы можете объединять или разделять сегменты.
Объединение
- Найдите два сегмента, идущих друг за другом, которые вы хотите объединить;
- Перейдите к первому сегменту;
- Нажмите Tools -> 1. Merge or split segments
Программа покажет предупреждение с результатом объединения. Можете нажать ОК для объединения, или отменить действие.
Разделение
- Найдите сегмент, который вы хотите разделить;
- В исходном тексте сегмента (над переводом) выделите вторую половину текста (от середины и до самого конца), которую вы хотите сделать отдельным сегментов;
- Нажмите Tools -> 1. Merge or split segments
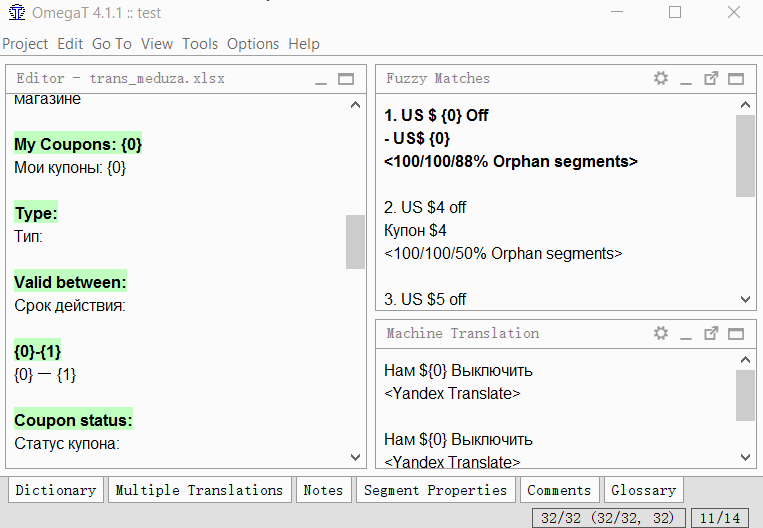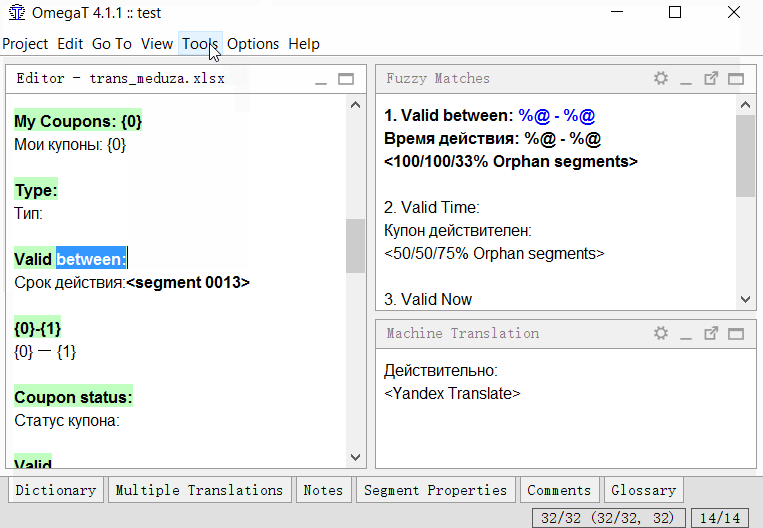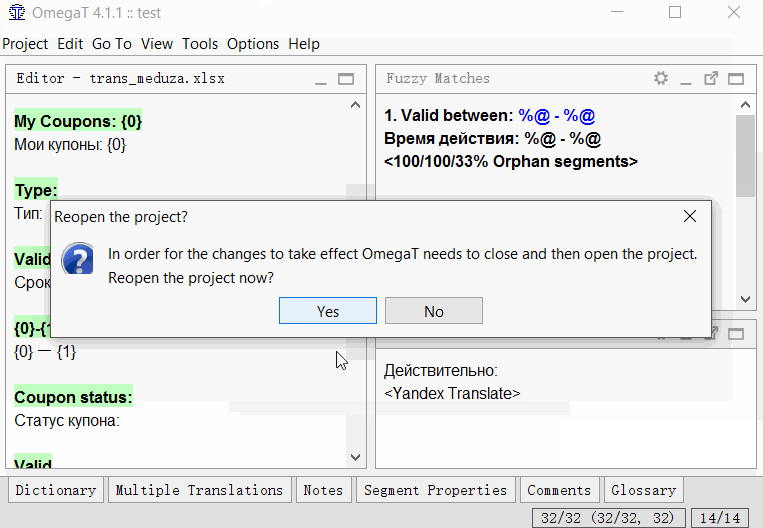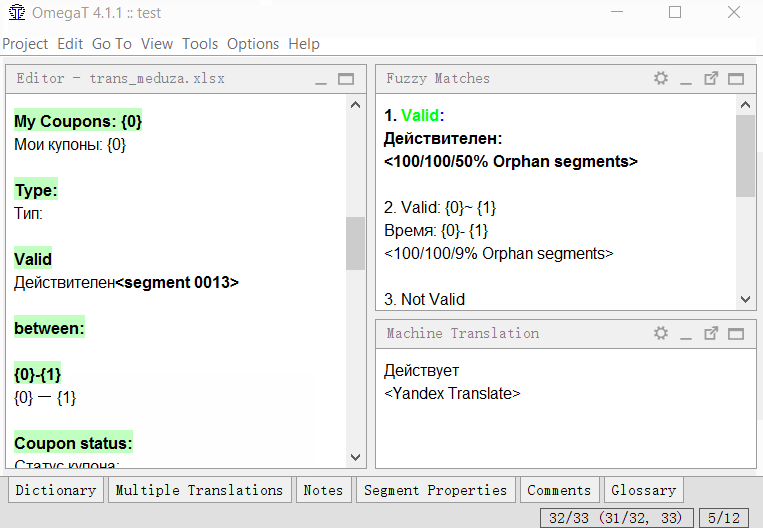
Программа покажет предупреждение с результатом разделения. Можете нажать ОК для разделения, или отменить действие.
Скрипт создаёт новое правило сегментации и применяет его к проекту. Скрипт очень далёк от идеала, и работает не всегда, но пока в OmegaT это единственный способ для точечного разделения/объединения сегментов.
Задавайте вопросы в комментариях, с радостью отвечу или дополню статью.


Владимир, большое спасибо за Ваш труд! С удовольствием и пользой читаю и использую в своей деятельности.
Вопрос: В Language Tools раздел Параметры, фильтр проверка Tags всегда выбрана и «засерена». Отключить невозможно. Может быть, это к лучшему и так и задумано?
На здоровье.
Не пойму что-то, где эта галка. В OmegaT? У меня версия 4.1.1, такого нет.
Спасибо за инструкцию! Почем-то не удается объединить сегменты указанным скриптом. В списке Tools -> Scripting после копирования скрипта в соответствующую папку не появляется Merge or split segments. Вроде бы на сайте проекта пишут Linux only, а у меня Windows. Может быть дело в этом?
У меня Windows, всё работает. Перезпускать OmegaT после добавления скрипта пробовали?
Конечно, в первую очередь. У Вас написано распаковать скрипт, т.е. Вы имеете ввиду архив, но, если я правильно понял, в архиве — исходники. После его распаковки в папку scripts программы у меня ничего не произошло. В описании же самого скрипта (merge.Readmi.pdf) сказано:
1) Download Merge 3 fies
2) Place Merge executable wherever you wish
3) Place the two groovy filles into the folder where your OmegaT scripts are located.
4) In OmegaT, open the merge.groovy and insert the correct path to Merge executable (instead of the/path/to/Merge_executable), save the script.
Под тремя файлами они, видимо, понимают merge.groovy, Merge_return.groovy и Merge. Последний, без расширения, получается и есть executable?
После выполнения третьего пункта в программе появилось название скрипта «Merge», в текст которого я прописал путь к файлу Merge согласно четвертому пункту. Однако после запуска скрипта — ошибка:
«The script «C:\Program Files\OmegaT\scripts\merge.groovy» is running…
JA
RU-RU
An error occurred
javax.script.ScriptException: javax.script.ScriptException: java.io.IOException: Cannot run program «C:/Program Files/OmegaT/scripts/Merge»: CreateProcess error=193, %1 не является приложением Win32″
В общем, я бы был очень благодарен за более детальное пояснение о том, как Вы устанавливали скрипт. В частности, такой ли у Вас набор файлов в архиве: https://imgur.com/a/X6yPm. А то у меня ощущение, что я не то или не туда копирую. Все-таки многие сегменты разбиваются некорректно и без их объединения переводить не очень удобно.
Ну конечно, mea culpa: дал ссылку не на тот скрипт. На самом деле, merge скрипт вот здесь https://sourceforge.net/projects/omegatscripts/files/aux%20scripts/merge_split.tar.bz2/download
Благодарю, скрипт установился!
Однако, появилась другая проблема. Программа не объединяет сегменты, хотя предупреждение с результатом появляется. Но после перезагрузки проекта сегменты остаются разделенными. При этом скрипт нормально объединяет те сегменты, которые он сам разделил. То есть если сначала скриптом разделить сегменты, то их он потом объединить может, а вот те, что изначально разделены — нет, несмотря на правильное предупреждение с результатом объединения. В чем, интересно, могло бы быть дело?
Она криво работает, да. Иногда и совсем не.
С другой стороны, если у вас очень много некорректной сегментации, стоит настроить правила, благо они очень гибкие.
Спасибо хозяину блога за знакомство с прекрасной прогой. Насчёт машинного перевода: не стоит заморачиваться с Яндексом — там лимит на бесплатные переводы. Просто скачайте небольшую прогу Qtranslate. Два лишних клика мышкой компенсируются бесплатным и неограниченным доступом к десятку источников машинного перевода, включая Яндекс и Гугль.
У бесплатного яндекс.переводчика лимит 10 миллионов символов в месяц. Я могу позавидовать такой производительности отдельно взятого человека переводчика 🙂 Более того, вся суть подключения машинного перевода к CAT — интеграция и скорость работы. Для получения машинного перевода в процессе работы нужно нажать ноль кнопок, а для использования его — один хоткей. Использование же внешней программы, типа Qtranslate, по юзабилити равнозначно использованию веб-версии любого из тех же переводчиков, потому что копи-альттаб-пейст-копи-альтаб-пейст. Уже не говоря о том, как именно «бесплатная» программа использует платные API гугл-транслейта (или вообще делает парсинг веб-страницы?).
Здравствуйте, спасибо вам большое. но вот же я не могу найти в омеге т3.6.0 куда вписать ключ от яндекса. Не могу обнаружить вообще ничего похожего на ваш скриншот. В том что по-русски зовется «параметры» дает только флажок поставить и пишет что API ключа нет, но куда его совать — не удалось найти.
Поставьте версию четвёртой ветки, это «latest». Там очень просто всё: поставили галочку напротив нужного машинного перевода, затем нажали кнопку configure и вставили ключ.
Спасибо за инфо.
При переводе локализации к Riot (OpenSource) возникло пару вопросов!
Огромное количество программ переводят «с нуля», хотя до сих пор уже все 1000 раз было переведено.
Вопрос: есть ли какая то «база данных» или веб-страница в интернете где TM/TMX уже есть и ТМ-файлы можно скачать?
Универсальной базы не существует, у всех свои гайдлайны. Но можно посидеть в интернете и насобирать для себя памятей перевода по душе. Одно время в открытый доступ были выложены многоязычные TMX от Mozilla Foundation (т.е. фаерфокс, тандербёрд и прочее), в направлении Английский-Любойязык, удобно было для локализации. У Microsoft тоже можно найти, и потом сконвертировать в нужный формат. В конце концов, если речь о простых терминах, то машинный перевод вполне справится.
Но это не отменяет того, что текст нужно вычитывать перед публикацией, отдать всё автозамене на откуп нельзя. Память перевода — инструмент переводчика, а не его замена.
Вот это и плохо для всех (Старт-апов, общества итд.), что нет универсальной базы. Тратятся большие ресурсы, совершенно не эффективно на однообразную и повторяющуюся работу. Общественный интеллект значительно эффективнее.
Конечно это на руку переводчикам которые этим на хлеб зарабатывают. Но я предполагаю, что через некоторое время такой работы, благодаря ИИ, нейросетям и тому подобному, станет значительно меньше. Теперь перейду от философии к нашему ограниченному человеческими слабостями миру.
Некоторое время назад был зарегистрирован на -> https://mymemory.translated.net/
На этом сервисе есть возможность на основе вашего файла для перевода .html, .doc, .txt создать .ТМХ файл.
Я пробовал на примере небольшого html EN-DE и это неплохо работает с ОмегаТ.
HowTO: Регистрируетесь на translated.net, открываете ссылку указанную выше а там на «Download a TMX», в новом окне выбираете имя, загружаете файл, выб. языки и создаете ТМХ
Хотелось бы узнать Ваше мнение!
Кстати там есть и API, правда я не пробовал.
На практике создать «универсальную память перевода» нельзя — как я уже говорил, разные требования, стилистика. Всё равно придётся редактировать текст. Хотя я видел подобные инициативы для игровой индустрии, например — кто-то собрал эксель-табличку на 10+ языках со стандартными элементами интерфейсов, особенно разных настроек.
По поводу сервиса — если есть идентичные по структуре файлы на двух языках, можно использовать встроенный в ту же омегу aligner и получить TMX. Онлайн-сервисов я избегаю, потому что не хочу дарить им свои тексты.
Владимир, может подскажете, как решить проблему? Перевожу в OmegaT страницу Википедии (очень показательный пример работы программы для студентов на втором в их жизни семинаре по CAT-программам :)). Но вот переведенная страница выстраивается не совсем корректно — картинки не отображаются, да и интерфейс не похож на оригинал. Хотя с текстом и гиперссылками полный порядок. М.б. есть какая-нибудь тонкая опция? Помню, что когда-то давно это получалось на ура.
И спасибо огромное за Ваш бесценный контент!
Я правильно понимаю, что вы сохранили всю страницу целиком в HTML, а потом загнали в Омегу?
Так делать не надо. Если цель перевода страницы из Википедии в том, чтобы, допустим, добавить к английский версии её русскую версию, то имеет смысл нажать на странице кноку Edit и скопировать исходный текст из редактора. Его уже и загонять в Омегу. Я сходу не нашёл фильтр для wikitext’а, но он довольно читаем и так, перевести его в Омеге проблем не составит.
На худой конец, просто выделите сам контент статьи (без интерфейса) и вставьте в Ворд. 🙂
Владимир, большое спасибо за быстрый и толковый ответ. Вы, конечно, правы. И если бы я выполняла заказ, то, наверное, так бы и сделала. Но хочется показать студентам, что при переводе текста с очень сложным форматированием программа скрывает все, что отвлекает переводчика, оставляя ему только текст. А потом — ррраз! — и совмещает все обратно 🙂 Когда-то именно такой трюк с Википедией произвел на меня неизгладимое впечатление при первом знакомстве с программой 🙂 Поэтому да, загнала в Omeg´у всю страницу HTML.
Но сейчас сама уже поколдовала, вроде бы через Mozill´у должно получиться.
Спасибо еще раз!
Сейчас форматирование HTML становится очень сложным. Слишком много скриптов, стилей, вставок и прочего. Конечно, студентам стоит показать ценность САТ, но нужно ещё научить выделать для перевода только нужное. Чтобы потом не утонуть в этой «ручной автоматизации» 🙂
Если хочется показать работу с документом «от» и «до», для примера можно взять какой-нибудь договор в *,docx. Если сегментация будет по предложениям, то можно заодно показать анализ файла и рассказать, сколько одинаковых фраз программа переведёт на лету.
Владимир, здравствуйте! Я пыталась подключить машинный перевод IBM Watson, но в нижней части окна, там, где вкладка «Машинный перевод», у меня появилось сообщение: «IBM Watson не доступен. Обратитесь к руководству OmegaT». Возможно ли это из-за того, что я использую версию OmegaT 4.3.2?
В настройках IBM Watson нужно указать API ключ и URL. Их можно найти в панели IBM Watson (на сайте, когда создаёте ключ). Проверьте, может быть что-то не так указали.