Fluent: локализация UI, практические примеры
Разберём ошибки в локализации AliExpress, LinkedIn и Instagram и посмотрим, как можно было бы использовать Fluent, чтобы сделать текст в UI красивым и естественным. Эти техники пригодятся не только в многоязычном окружении, но и в приложении с одной локалью. Сначала посмотрим, какие способы используются для форматирования строк с переменными, а потом разберём конкретные кейсы.
Способы форматирования строк с переменными
Конкатенация строк
Самый старый и самый плохой способ — конкатенация нескольких строк в одно предложение, например:
userName = Василий
userOstavil = оставил
commentCount = 15
commentVkonce = комментариевСкладываем эти строки и получаем: Василий оставил 15 комментариев.. У этого способа множество проблем, но с точки зрения UX-райтера или локализатора главная — невозможность поменять последовательность значений без вмешательства разработчика, а также кривой результат, когда значение переменной выходит за рамки предусмотренного, например: Елена оставил 1 комментариев.
Переменные с фиксированной последовательностью
Чуть более продвинутый способ записи — использование переменных внутри текстовой строки. В самом простом случае все переменные выглядят одинаково, и какую куда вставлять — решает их порядок появления в тексте:
comments = %s оставил %s комментариев.Такой подход даёт локализаторам чуть больше свободы действий, но может привести к неприятным ошибкам. Например, нельзя выкинуть переменную или поменять их местами (очень важно при переводе на другой язык, когда грамматика диктует другую последовательность). Кроме того, без контекста порой невозможно понять, что означает %s, что может привести к некорректным переводам.
Уникальные переменные
Наиболее распространённый способ генерации предложений:
comments = {$userName} оставил {$commentsNumber} комментариев.Здесь уже можно менять переменные местами, и (при нормальном наименовании) они дают представление о финальном результате. Однако во флективных языках вроде русского, где, к примеру, от рода предыдущего слова зависит окончание следующего, сгенерировать правильный текст бывает проблематично — приходится просить разработчика писать разные варианты строк под разные ситуации. Это тратит время разработчика на «костыль» для каждой ситуации и создаёт множество дублирующих ключей, ведь не во всех языках будет разница между разными родами. Когда разработчик не может помочь, прибегают к самым некрасивым методам, вроде:
comments = {$userName} оставил(а) {$commentsNumber} комментарий(ев).Здесь на помощь может прийти проект Fluent от Mozilla, который унифицирует запись подобных строк и позволяет локализатору (переводчику) добавлять альтернативные варианты отображения текста в зависимости от значения переменной. Я уже публиковал перевод подробной статьи про Fluent на Хабре и переводил документацию для переводчиков. В этой же статье я хочу показать примеры того, как Fluent мог бы улучшить локализацию таких популярных продуктов, как AliExpress, Instagram и LinkedIn, с конкретными примерами.
AliExpress
Селекторы для числительных
Разберём самый простой пример — карточку товара на AliExpress. Сразу под названием видно, сколько раз покупатели проголосовали за этот товар и сколько раз его заказывали.
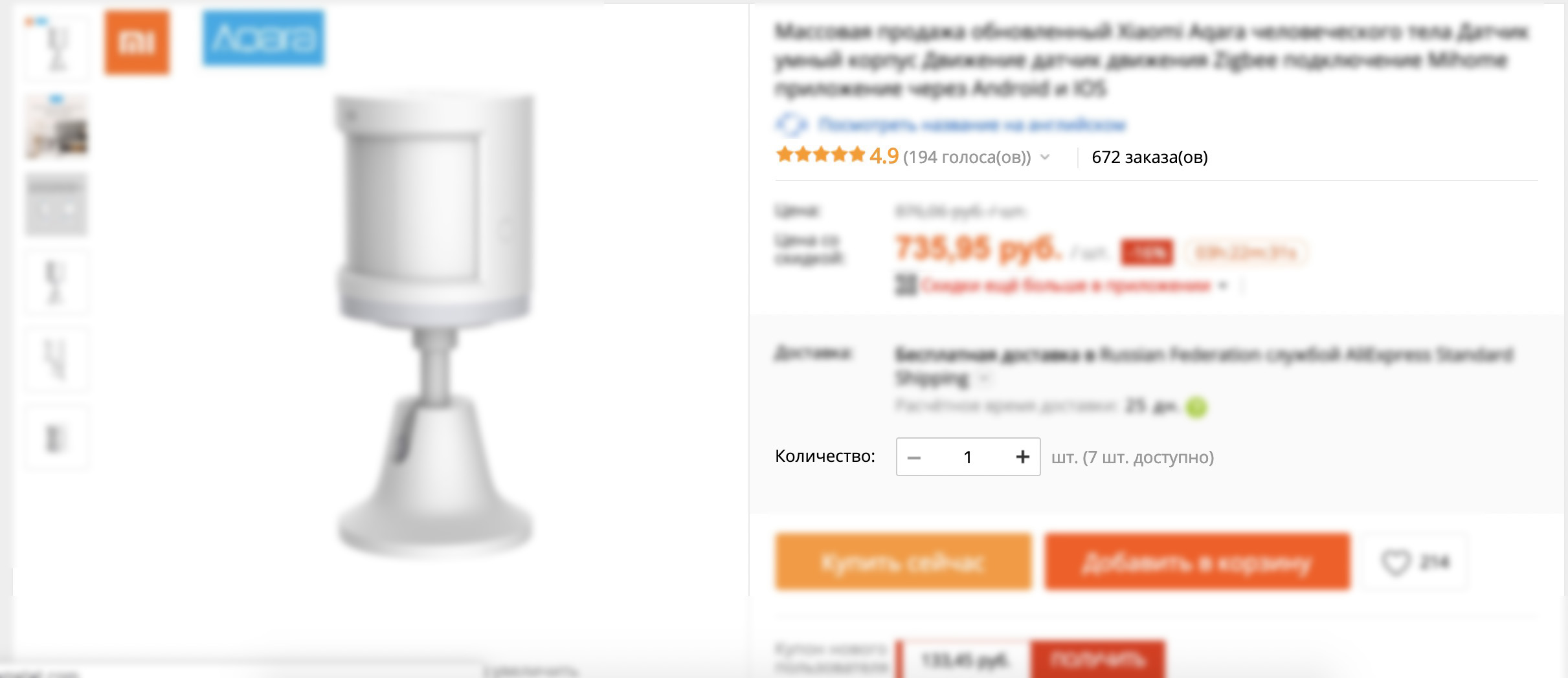
В коде сайта текущие фразы для «голосов» и «заказов» записаны примерно так:
reviews = {$reviewsCount} голоса(ов))
orders = {$ordersCount} заказа(ов)Проблемы очевидны: текст не учитывает написание слов «заказ» и «голос» в зависимости от числительного. Если бы AliExpress использовал синтаксис Fluent, то переводчик мог бы записать текст вот так:
reviews =
{$reviewsCount ->
[0] Ни одного голоса
[1] Один голос
[one] {$reviewsCount} голос
[few] {$reviewsCount} голоса
*[many] {$reviewsCount} голосов
}Как это работает?
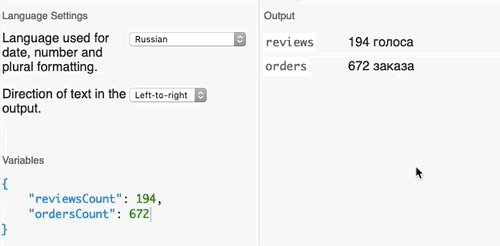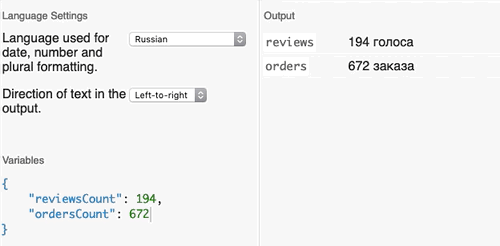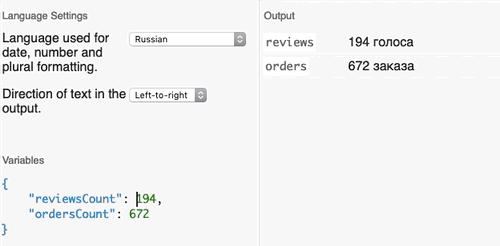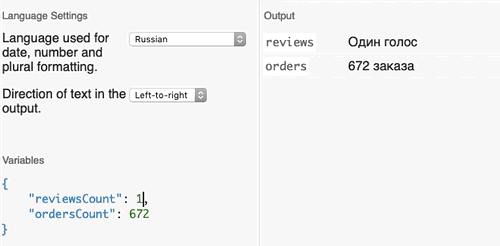
В самом начале строки используется селектор, который выбирает текст в зависимости от значения переменной reviewCount. При значении, равном нулю ([0]), будет выведена строка «Ни одного голоса». Обратите внимание, что переменная числа не используется вообще — в ней нет нужды, такая фраза лучше считывается словами. Если переменная равна единице ([1]), появится надпись «Один голос». Значения [one], [few] и [many] взяты из категорий множественных чисел CLDR, которые поддерживаются синтаксисом Fluent. К примеру, [one] означает, что в переменной используется число с единицей на конце — например, 201; [few] — числа от 2 до 4, от 22 до 24 и так далее.
То же самое сделаем для количества заказов, добавив «пасхалку» на тот случай, если выпадет число 666:
orders =
{$ordersCount ->
[0] Ни одного заказа
[1] Один заказ
[one] {$ordersCount} заказ
[few] {$ordersCount} заказа
[666] Тысяча чертей и 666 заказов
*[many] {$ordersCount} заказов
}Можете попробовать скопировать этот текст в песочницу Fluent и сами поиграть с текстом и переменными. Значения переменных для песочницы:
{
"ordersCount": 672,
"reviewsCount": 194
}Объединение селекторов
На странице поиска товара встречается похожий текст с отзывами и заказами, который записан примерно так:
orders-reviews = Отзывы ({$reviewsCount}) | По заказам ({$ordersCount})
Используя синтаксис Fluent, его можно записать вот так, используя несколько селекторов в одной строке:
orders-reviews =
{$reviewsCount ->
[0] Ни одного голоса
[1] Один голос
[one] {$reviewsCount} голос
[few] {$reviewsCount} голоса
*[many] {$reviewsCount} голосов
} по {$ordersCount ->
[1] одному заказу
[one] {$ordersCount} заказу
[few] {$ordersCount} заказам
*[many] {$ordersCount} заказам
}Форматирование времени
Перейдём к более сложной магии — отображению времени. Некоторые разработчики решают проблему «в лоб» и пишут собственный шаблон, как в этом случае:
order-time = hh:mm MM. dd yyyy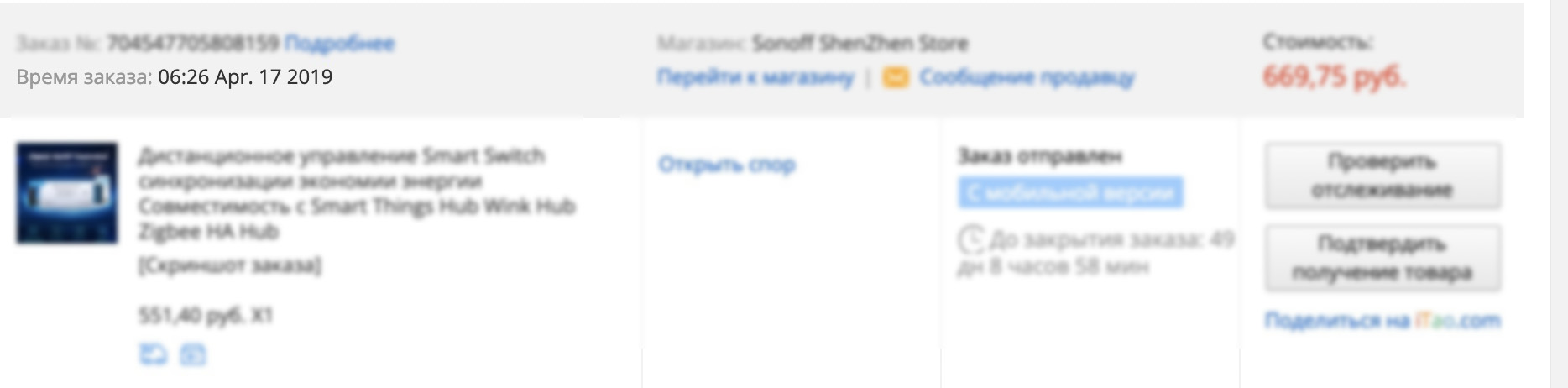
У него целая куча проблем — даже написание месяца не локализовано, не говоря уже о разных региональных форматах записи времени. Синтаксис Fluent поддерживает библиотеки форматов вышеупомянутой CLDR, достаточно записать строку с нужными параметрами форматирования и передать в неё время:
order-time =
Время заказа: { DATETIME($date, month: "long", year: "numeric", day: "numeric", weekday: "long") }В качестве переменной времени укажем время в формате Unix Time (конвертер):
{
"date": 556593884000
}На выходе мы получим:
order-time =
Время заказа: вторник, 30 апреля 2019 г.Прелесть в том, что для другого языка — например, английского — форматирование будет соответствовать принятому там стандарту:
order-time =
Order time: Tuesday, April 30, 2019LinkedIn, Instagram
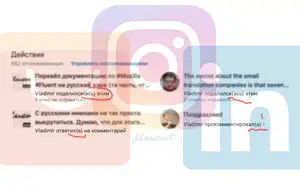
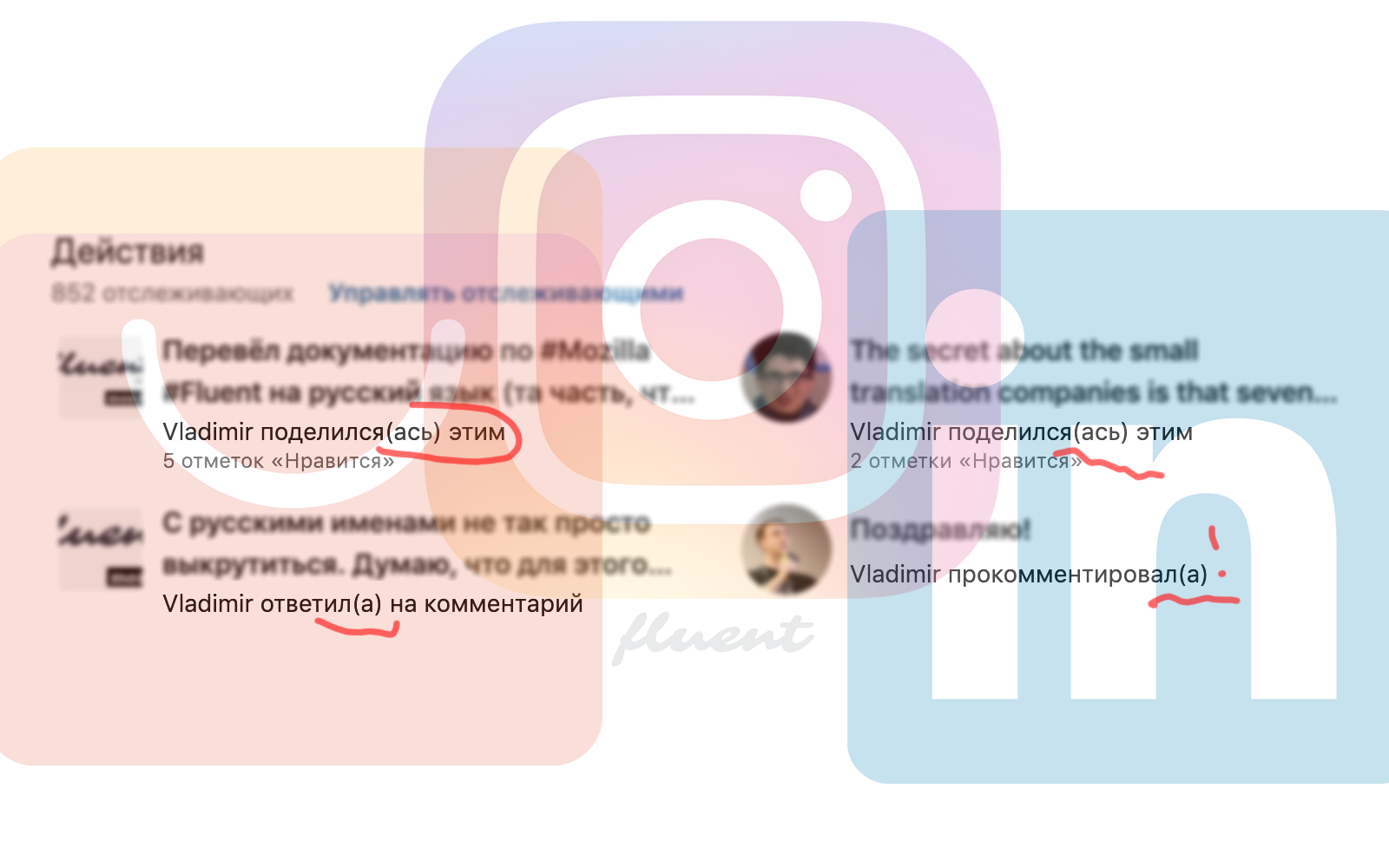
Род
Деловая соцсеть LinkedIn прекрасно знает пол каждого пользователя — здесь не принято его скрывать. Тем не менее, в русской локализации она всегда сомневается, используя тяжёлые конструкции:
recommendation-date =
{ DATETIME($reviewDate, month: "long", year: "numeric", day: "numeric") },
{$reviewerFirstName} был(а) {$usersRelationship} участника {$userFirstName}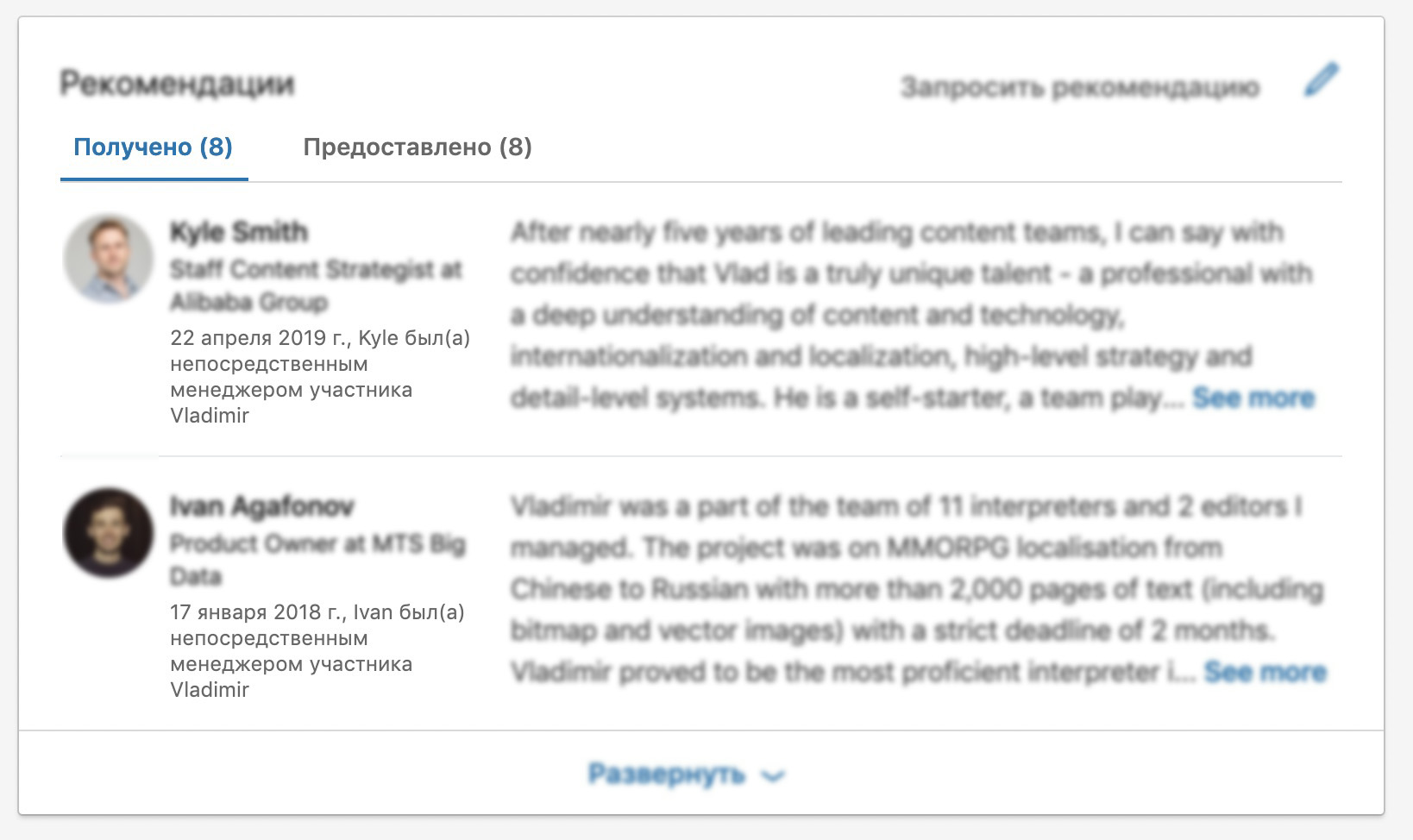
Для форматирования строки в неё передаются примерно такие переменные:
{
"reviewDate": 1555902684000,
"reviewerFirstName": "Kyle",
"reviewerRelationship": "непосредственным менеджером",
"userFirstName": "Vladimir"
}Разработчикам будет несложно добавить переменную для пола пользователя, которая будет передаваться в строку для форматирования: {"reviewerGender": "male"}. И тогда строка в синтаксисе Fluent будет выглядеть вот так:
recommendation-date =
{ DATETIME($reviewDate, month: "long", year: "numeric", day: "numeric") },
{$reviewerFirstName} {$reviewerGender ->
*[male] был
[female] была
} {$usersRelationship} участника {$userFirstName}То же самое происходит в Instagram:
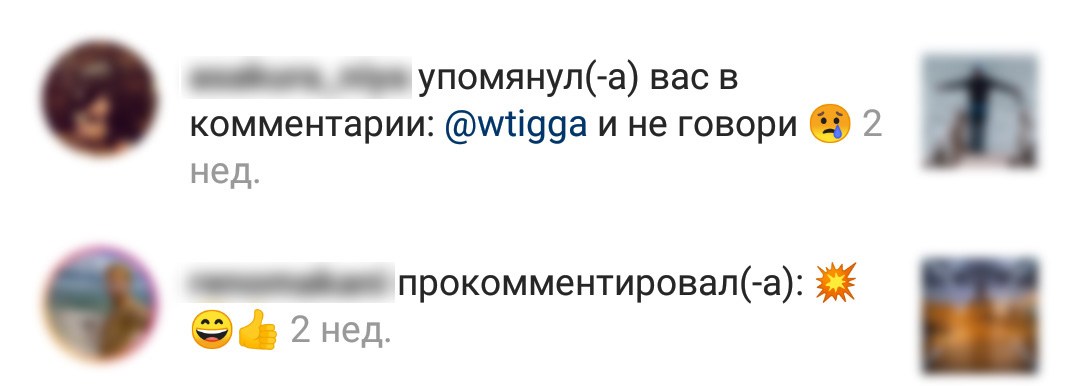
Сейчас там используется строка вроде:
mention = {$mentionUser} упомянул(-а) вас в комментарии: {$commentText}Конечно, в Instagram, в отличие от LinkedIn, указывать пол не обязательно, поэтому можно добавить третью опцию [other], которая в непонятных случаях будет выдавать соответствующую строку:
mention = {$mentionUser} {$mentionUserGender ->
*[male] упомянул
[female] упомянула
[other] упомянул(а)
} вас в комментарии: {$commentText}Например:
Василий упомянул вас в комментарии: крутяк!Елена упомянула вас в комментарии: сам дурак :-(Kagino упомянул(а) вас в комментарии: Всем чмоки, болезные