
Как переводить документ в Word и не париться с форматированием? Как не переводить одно и то же? Как сохранять единообразие? Как не покупать дорогие программы? Как работать эффективно и быстро?
Если вы знакомы с Trados, MemoQ или CrowdIn, переходите сразу к инструкции по установке. Если же это новые для вас слова — добро пожаловать в прекрасный мир Computer Aided Translation.
- О переводе с помощью компьютера
- Какие бывают CAT-программы?
- Что умеет OmegaT?
- Установка
- Проверка правописания
- Как создать проект
- Что это за папки?
- Как добавить файлы
- Интерфейс
- Как переводить
- Нечёткие совпадения Fuzzy Matches
- Автоматический перевод одинаковых сегментов
- Глоссарий
- Как сохранить файлы
О переводе с помощью компьютера
Фраза «перевод с помощью компьютера» у многих прочно ассоциируется с машинным переводом. Google Translate — это именно машинный перевод, компьютер переводит за вас, вы только должны подавать ему исходный текст.
CAT (Computer Aided Translation — «перевод с помощью компьютера») — подход к переводу, когда компьютер только помогает в работе, автоматизируя рутинные процессы. CAT-программы разделяют исходный текст на сегменты — строки, предложения, параграфы или абзацы. Человек переводит сегмент один за другим, а перевод сохраняется в специальную базу данных — память перевода (translation memory, TM). Если переводчику встретится похожий сегмент, программа покажет подсказку или возможный перевод. А одинаковые сегменты программа может переводить сама.
Особенно хорошо CAT помогает в переводе инструкций, юридических документов, интерфейсов программ — там, где похожие формулировки встречаются очень часто. В художественном переводе помощь будет не так очевидна, но об этом позже.
Чем больше текстов по схожей тематике вы переводите, тем больше накапливается переводов в базе данных, чаще появляются подсказки. За годы может накопиться такая база, что в новом документе половина перевода будет готова «сама по себе».
Когда перевод закончен, программа создаёт документ, идентичный оригиналу — сохраняя структуру и форматирование, но заменяя исходный текст на ваш перевод.
CAT-программы не изменяют исходный документ, поэтому необратимо испортить документ невозможно. На выходе будет полностью переведённый файл.
Какие бывают CAT-программы?
Разные. Trados, MemoQ — дорогие корпоративные комплексы, устанавливаются на компьютер. CrowdIn, Tolmach и другие — работают прямо в браузере. Как правило, всё стоит денег, либо есть ограничения по объёму проектов.
Но не всё так плохо: я уже лет восемь пользуюсь OmegaT, бесплатной программой с открытым исходным кодом, которая работает на Windows, Mac и Linux-системах и постоянно совершенствуется сообществом. Работаю в ней с китайским, английским и русским языками.
Что умеет OmegaT?

www.omegat.org
Freeware (GPLv3), open source
Windows, macOS, Linux

Умеет всё, что описано в первой главе — помогать переводчику в работе, и разные другие мелочи.
Форматы файлов
- Microsoft Word, Excel, PowerPoint (только новые .xlsx, .docx и *.pptx, старые нужно сначала сконвертировать)
- OpenOffice .ods, .odt и прочие
- Текстовые файлы .txt, .rtf
- Текстовые файлы структуры key=value (*.ini и подобные)
- HTML
- Файлы с XML-структурой (можно настроить самому)
- И многие другие.
Языки
Любые. Практически всё, что есть в Unicode.
Для редких языков может понадобиться корректировка правил сегментирования, но всё решается.
Я не буду пересказывать инструкцию. Она полная и содержательная, и ознакомиться с ней очень важно. Дальше будут лишь основные операции с программой, которые помогут начать работу.
Установка
Скачайте дистрибутив с сайта omegat.org. Я буду использовать англоязычную версию 4.1.1 ветки Latest для Windows. Для запуска требуется Java. Если не уверены, есть ли она у вас, качайте версию с пометкой JRE. Не пугайтесь надписи Beta, программа работает более чем стабильно.
Проверка правописания
После установки программа готова к работе, но по-умолчанию не хватает проверки орфографии.
- Запускаем OmegaT
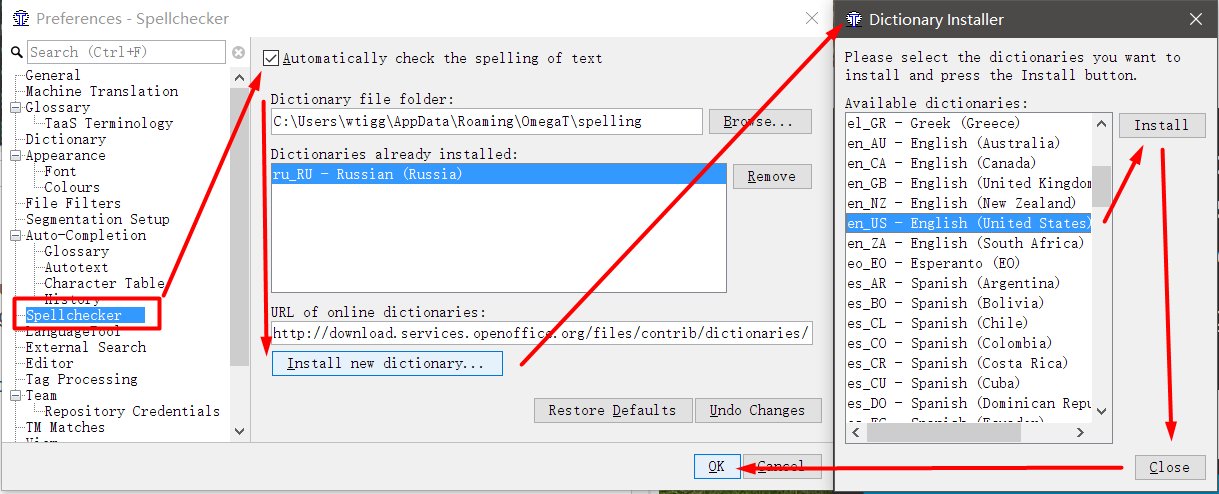
- Переходим в Options -> Preferences -> Spellchecker
- Ставим галку Automatically check the spelling of text
- Нажимаем Install new dictionary
- Выбираем язык (например, ru_RU для русского), нажимаем Install
- Жмём Close. В списке видим русский язык.
- Выходим из настроек.

Как создать проект
OmegaT работает не с отдельными файлами, а с «проектами». Проект — набор папок с определённой структурой. Чтобы перевести файл, нужно создать проект, а потом добавить туда файл.
- Запускаем OmegaT
- Project -> New, выбираем место для сохранения и имя проекта. Я рекомендую давать проектам осмысленные имена и указывать в них языковую пару. Например, Test-Project_EN-RU.
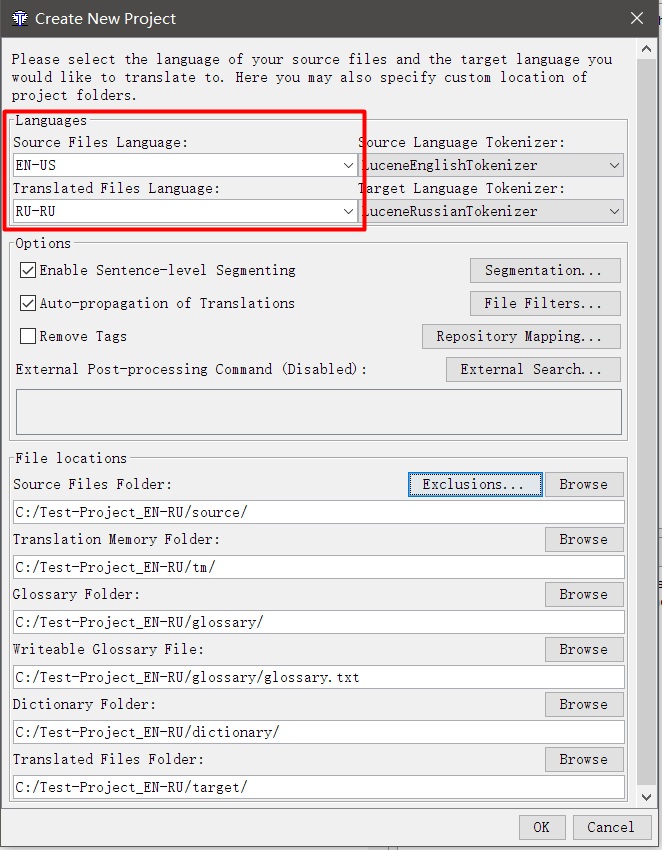
- В появившемся окне укажите языковую пару
Source Files Language — язык, с которого вы переводите; Target Files Language — язык, на который вы переводите. Указывать нужно в двух- или четырёх-буквенном коде. Например, RU — русский язык, а RU-RU и RU-BY — уточнение, что это русский из РФ и русский из Белорусии. Чтобы работала проверка правописания, код должен совпадать с кодом, указанным в настройках орфографии (если в орфографии установлен RU-RU, а в проекте будет RU, то проверка работать не будет). - Ниже отметьте галочки Enable Sentence-level Segmenting (делить сегменты по предложениям, а не по абзацам) и Auto-propagation of Translations (подставлять переводы автоматически). Галочку Remove Tags (убирать теги) лучше снять, я объясню её работу позже.
- Нажимаем ОК.


Что это за папки?
Внутри папки проекта есть несколько под-директорий:
- dictionary — можно добавить словари в формате StarDict; функция довольно бесполезная.
- glossary — база терминов по проекту, об этом позже;
- omegat — память перевода и резервные копии проекта;
- source — папка с иходными файлами;
- target — папка, в которой будут появляться переводы;
- tm — папка для дополнительных памятей перевода, об этом позже.
а так же файл omegat.project с конфигурацией текущего проекта.
Как добавить файлы
Создав проект, вы увидите такое окно:
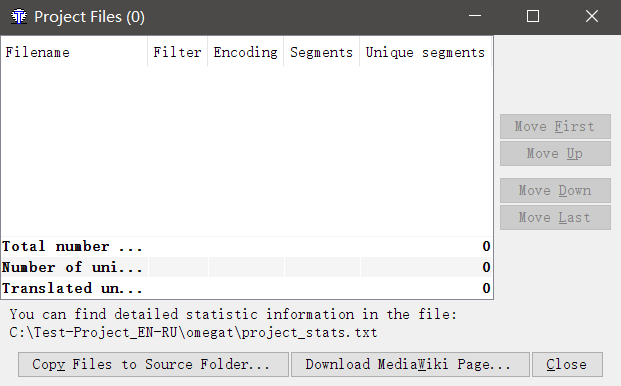

Нажмите Copy Files to Source Folder и выберите файлы, которые вы хотите перевести.
Файлы будут скопированы в папку \source\ только что созданного проекта. Вы можете добавить туда файлы вручную. Просто скопируйте файлы в \source\ через проводник.
Для примера я создал два файла — Excel и Word, на которых я буду показывать работу OmegaT.
Интерфейс
OmegaT запущена, файлы добавлены. Давайте посмотрим, как они выглядят в программе.
Вот исходный документ в Word. Здесь видны заголовок, абзацы, форматирование (жирный шрифт, ссылки, подчёркивания).


А вот как он выглядит в OmegaT:
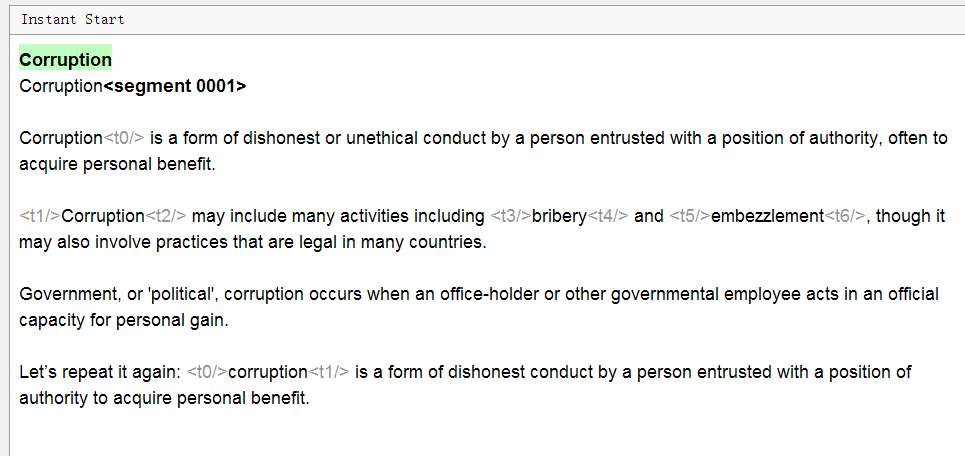

Обратите внимание: весь текст разделён на предложения, форматирования не видно, появились какие-то теги серого цвета, а заголовок заголовок дублируется. В чём дело?
- Текст разделился на сегменты
Каждое предолжение выделилось в отдельный сегмент. Правила сегментации можно настроить самостоятельно при необходимости. - Форматирование в OmegaT не видно, его заменяют теги
Они представляют собой сокращения тегов из Word, которые иначе могли выглядеть как <t>. Чтобы сохранить оригинальное форматирование, нужно оставлять эти теги как есть, вписывая перевод между тегами по той же логике, что и в оригинале.
Опция Remove tags в настройках проекта убирает теги вместе с форматированием. Не рекомендуется использовать, если важно сохранить оригинальное форматирование. - Заголовок не дублируется.
На самом деле, сверху (в зелёном цвете) всегда отображается текст на исходном языке, изменить его нельзя. Под ним находится текстовое поле, куда по-умолчанию скопирован тот же самый текст. Его нужно удалить и вписать перевод.
Кроме того, в правой части программы есть ещё два сектора: Fuzzy Matches и Glossary (словарь проекта).
Fuzzy Matches (нечёткие совпадения) — результаты поиска по базе данных проекта. Там будут отображаться подсказки по переводу, основанные на ваших предыдущих переводах.
Glossary (словарь проекта) — результат поиска по глоссарию, который вы составляете самостоятельно. В отличие от памяти перевода, это не готовый текст, а лишь подсказки по определённым терминам. Это мощный инструмент, который помогает сохранять единообразие в терминологии.
Как переводить
- Дважды кликните на сегмент для перевода
Под оригинальным текстом появится редактируемая текстовая строка, курсор будет в её начале, а в строке будет продублирован оригинальный текст. - Впишите свой перевод
- Нажмите Enter
При нажатии перевод сохранится, а курсор перейдёт к следующему сегменту.
![]()

Повторяйте, пока не закончите документ. В любой момент можно вернуться к предыдущему сегменту, просто дважды щёлкнув на него.
В правом нижнем углу есть удобный индикатор прогресса. Кликните на него, чтобы переключить режим просмотра.


В этой строке указано, что в текущем файле переведено 5,8% уникальных сегментов, осталось перевести ещё 1382. А суммарно в проекте переведено 63% сегментов, осталось 1756, а их общее число в проекте — 5979.


Во втором режиме на иллюстрации сказано, что в файле из 1592 уникальных сегментов переведено 146, а в проекте из 4748 уникальных сегментов переведено 2992. Всего сегментов (включая повторы) — 5979.
Цифры 14/14 в конце не относятся к счётчику проекта. Это — индикатор длины сегмента с которым вы работаете. Он говорит, что в оригинале было 14 символов, и в переводе их тоже 14. Эта функция полезна в тех случаях, когда нужно строго соблюдать длину строки, например при переводе интерфейса программ.
Нечёткие совпадения Fuzzy Matches
Самый главный инструмент любого CAT-приложения, ради этого они и существуют.
Объясню на примере:
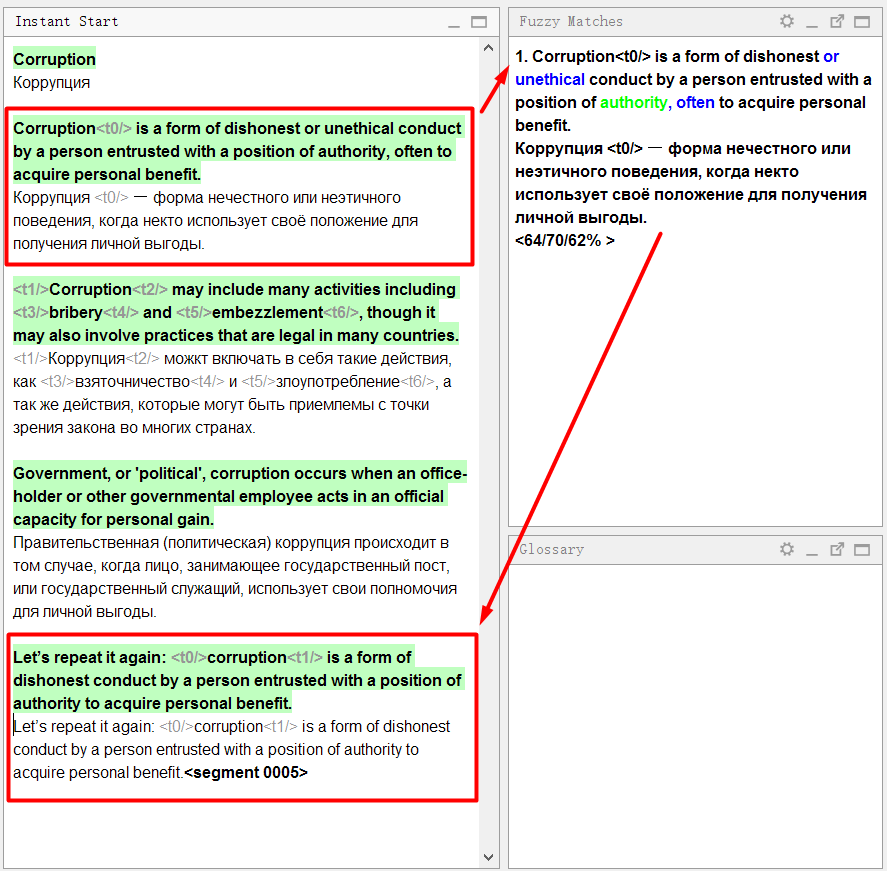

В документе-образце первое предложение очень похоже на четвёртое. Я шёл по порядку и перевёл первое предложение. Когда же я дошёл до четвёртого, программа сразу же показала нечёткое совпадение:
Посмотрите внимательно на панель совпадений:
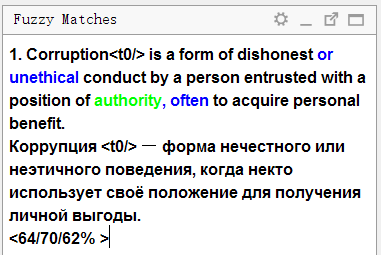

В верхней части отображается текст на исходном языке, который был сохранён в памяти перевода. Синим цветом выделны слова, которые присутствуют в памяти перевода, но отсутствуют в текущем предложении (с которым сравнивается совпадение), зелёным — слова, расположенные рядом с недостающими частями.
Ниже будет перевод, сохранённый в памяти. Если нажать Ctrl+R, то он скопируется в поле для перевода.
Ещё ниже указаны три числа в процентах. Они означают степень совпадения между предложением и памятью перевода. Подробнее о механизме вычислений можно прочитать в справке к OmegaT.
Автоматический перевод одинаковых сегментов
Конечно, если механизм Fuzzy Match найдёт 100% совпадение, он может вставить его самостоятельно. Для примера возьмём ещё один файл, на этот раз в Excel. Примерно в таком виде нередко приходит заказ на перевод интерфейса какого-нибудь сайта или программы.
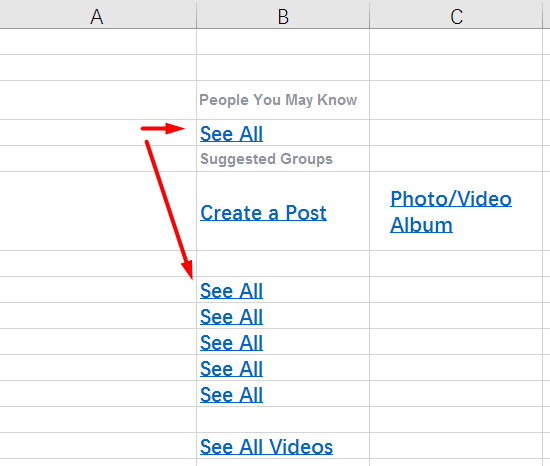

А вот как файл выглядит в OmegaT:
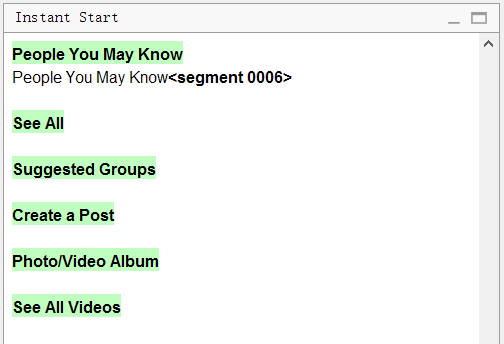

Обратите внимание, что в оригинале было шесть строчек See All. Программа убрала все дубликаты, оставив лишь одну строчку. Достаточно перевести её одну, и остальные сегменты тоже переведутся.
Глоссарий
Глоссарий работает очень просто. Сначала вы добавляете в него слова (оригинал и перевод). Теперь, когда слово встретится в тексте, в окошке Glossary сразу же отобразится подсказка.
Таким образом, когда в новом предложении появился какой-то термин, вы сразу будете знать, как именно следует его переводить. Например, если при переводе интерфейса программы всегда нужно писать «Хорошо» вместо «ОК», достаточно добавить в словарь слово «ОК» с переводом «Хорошо». Добавив несколько сотен слов в проект, вы значительно облегчите себе жизнь.
Чтобы добавить слово в глоссарий, выделите его, щёлкните правой кнопкой и выберите Add Glossary Entry.
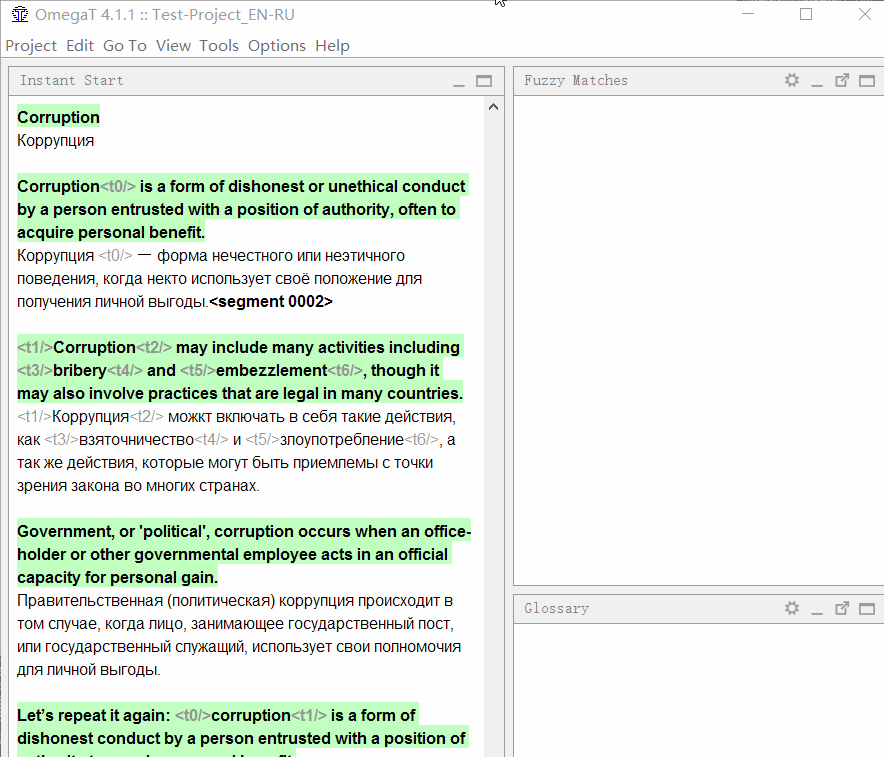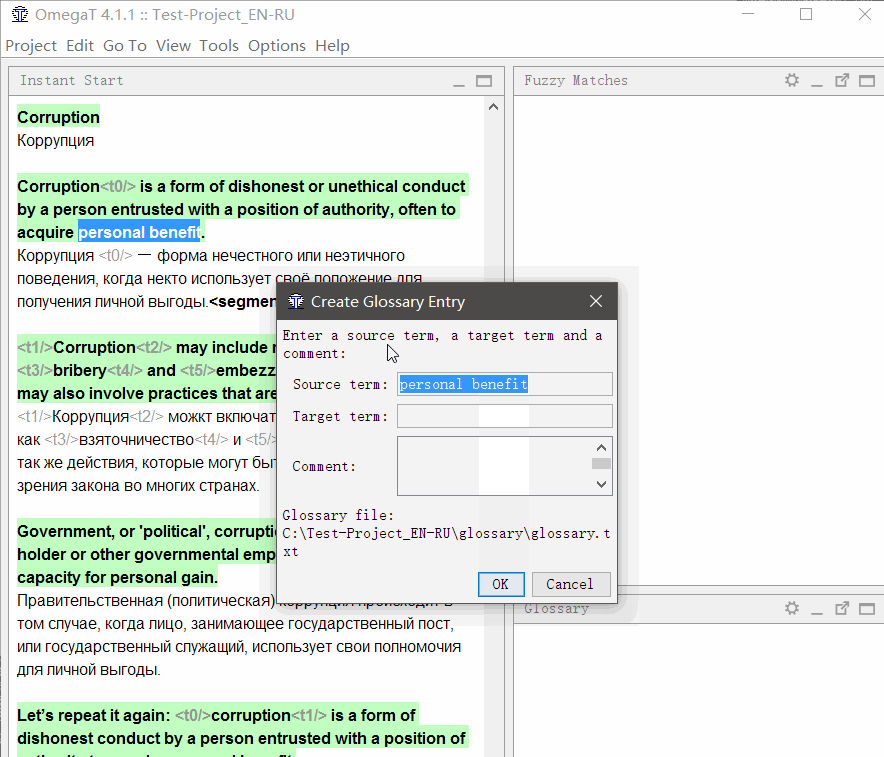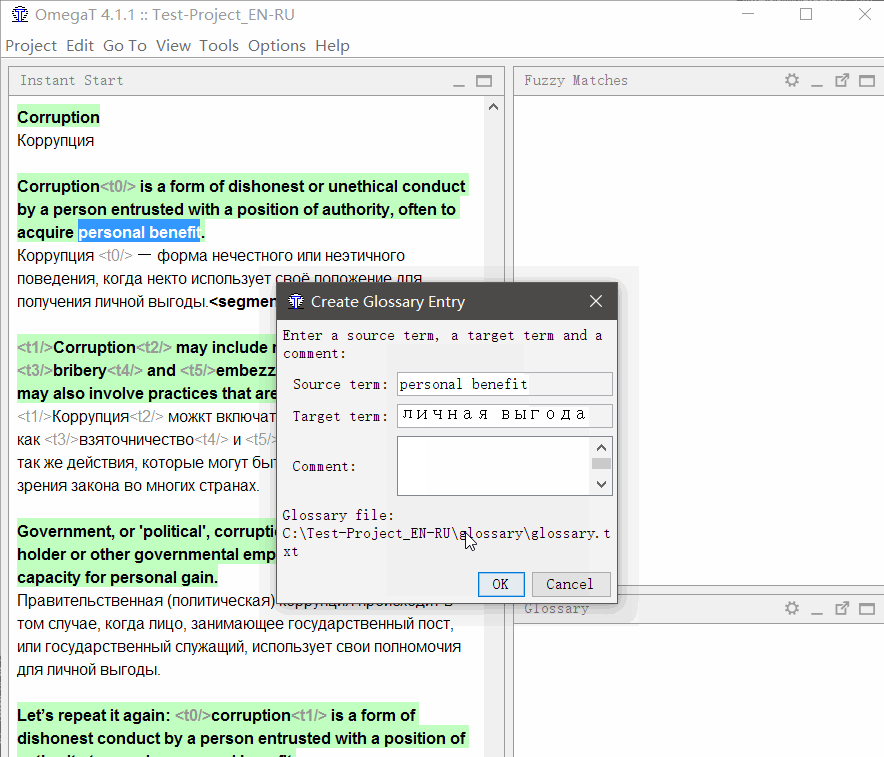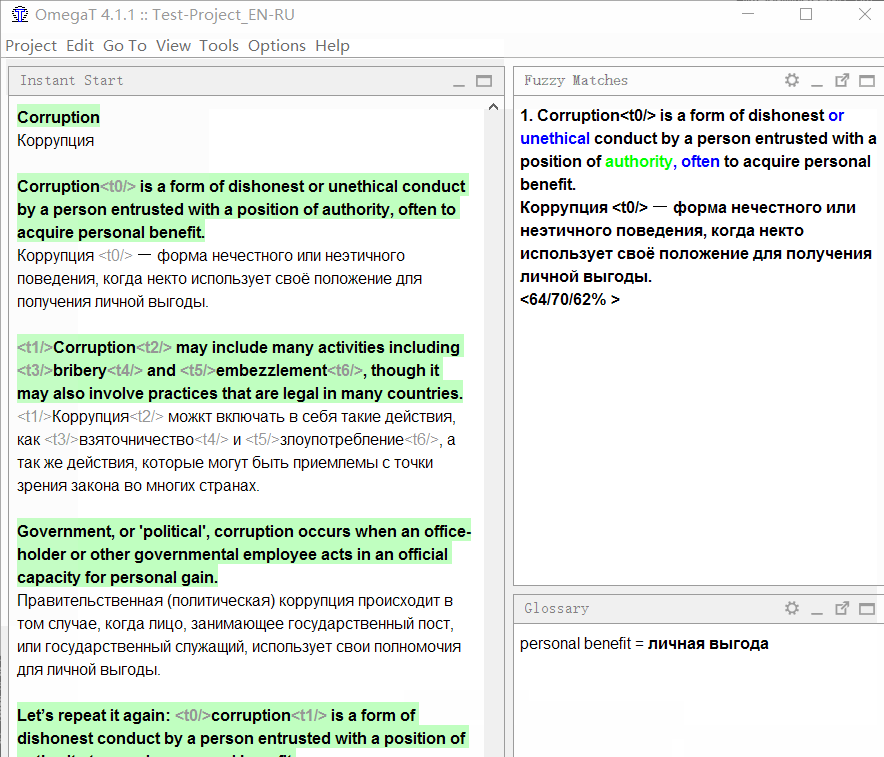

Кроме того, слова можно добавить массово в файл \glossary\glossary.txt в формате «оригинал табуляция перевод» (подойдёт таблица в Excel, сохранённая в формате tab-delimited *.csv)
Как сохранить
Пункт Project -> Save означает «сохранение проекта», т.е. запись всех переводов в файл базы данных. А чтобы получить готовый файл, нужно выбрать Project -> Create translated documents.
![]()

По этой команде OmegaT создаст новый файл в папке \target\ с тем же именем, что и оригинал, а весь текст поменяет на перевод. Если какие-то сегменты вы не перевели, то в файле на их месте будет оригинальный текст.
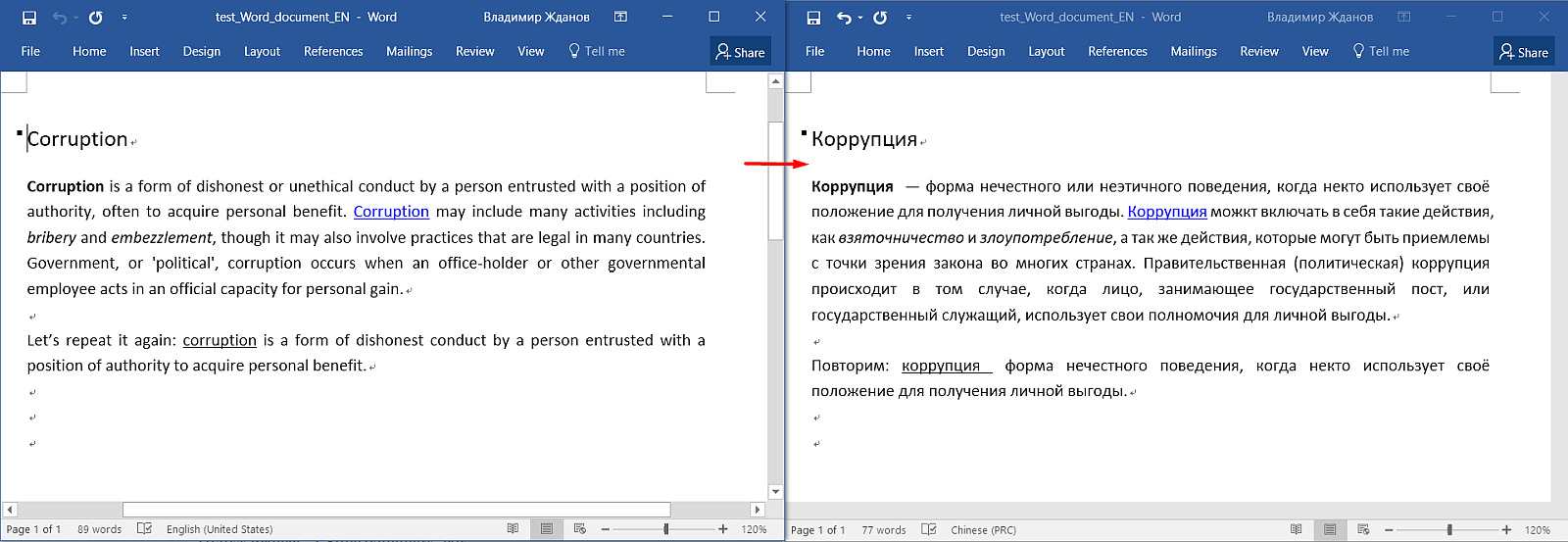

Продолжение
В следующей части я расскажу о том, как подключить машинный перевод, проверить текст на ошибки, как создать свою ТМ и какие не очевидные проблемы могут возникнуть в работе с программой.